Сотрудник Level 9 начал выкладывать на GitHub весь архив компании

Замечательная британская компания Level 9 Computing в далёких 80-х славилась своими отличными текстовыми квестами. Игры, которые выпускали британцы, от большинства конкурентов отличал отличный английский язык, огромные объёмы текстов и мощный парсер, понимавший много слов и не самые банальные лексические конструкции. Довольно быстро в играх Level 9 появилась и графика — поначалу простенькая, но со временем всё более и более красочная.
Благодаря собственному языку A-code компания могла быстро портировать свои игры на большое количество платформ. Вот их примерный список: ZX Spectrum, Commodore 64, BBC Micro, Nascom, Oric, Atari 8-bit, Camputers Lynx, RML 380Z, Amstrad CPC, MSX, Amiga, Apple II, Memotech MTX и Enterprise.

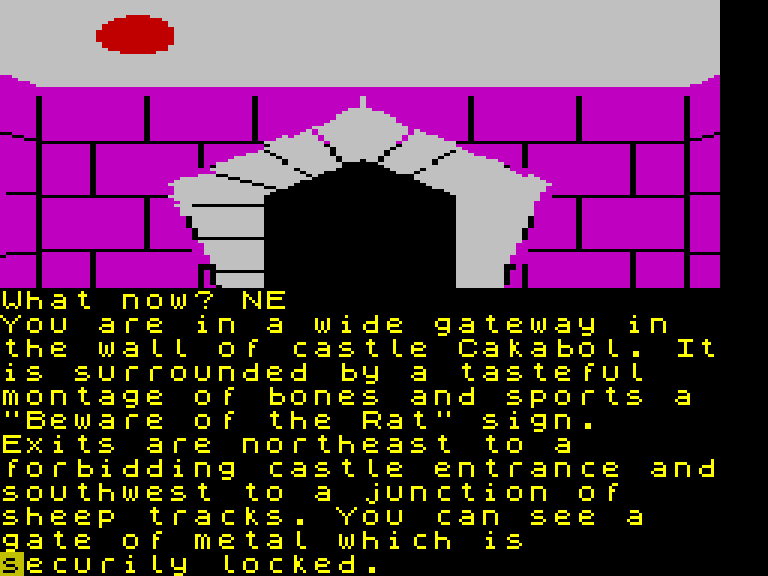
Подобно своим коллегам из США, компании Inforcom, парни из Level 9 писали свои квесты на этом «A-коде», а для каждого компьютера ровно один раз делали «А-машину», которая и интерпретировала «А-код» с учётом архитектуры. А годный компрессор текстов позволял запихивать даже самые большие приключения в крошечную памятью 8-битных компьютеров той эпохи.
За свои 10 лет жизни Level 9 выпустила две десятка квестов, некоторые из которых были объединены в трилогии. Например:
- Jewels of Darkness (Colossal Adventure, Adventure Quest, Dungeon Adventure)
- Silicon Dreams (Snowball, Return to Eden, The Worm in Paradise)
- Time and Magik (Lords of Time, Red Moon, The Price of Magik).
И вот недавно сотрудник компании Майк Остин начал выкладывать на GitHub весь найденный архив Level 9: от мануалов до исходных кодов самих игр на языке A-code. Документация и исходники самого «А-кода» тоже имеются, не переживайте. Архив основан на более чем 1000 дискет, половину из которых уже прочитали благодаря эмулятору Atari ST. Вторая половина либо не читается, либо ей этот процесс ещё предстоит.
Архив более-менее упорядочен: в папке floppy disk archive находятся, вы не поверите, образы дискет; в game sources — исходники конкретных игр; в sys sources — исходники А-кода и прочих системных штук; в sys sources/docs находится преимущественно документация, хотя в дурном формате первого «Ворда».

https://idpixel.ru/games/k/knightorc/images/knightorc_6s_2x.jpg
Покопаться в архиве на GitHub можно прямо сейчас — это дико интересное занятие. Только держите в уме, что работа Майка далека от завершения: ему предстоит прочитать ещё кучу дискет, отсканировать килограммы бумаги (около 20 000 листов), перевести документацию в какой-нибудь современный формат и так далее.
В любом случае, товарищу за такое сохранение цифрового наследия можно сказать только огромное спасибо. Надеемся, что все дискеты и мануалы после обработки он отдаст в какой-нибудь надёжный музей, где всё это добро будут хранить как зеницу ока.
О проекте
«Идеальный пиксель» — новостной проект о ретро-играх и ретро-технике. Восьмибитные игры, шестнадцатибитные консоли, домашние компьютеры с играми на кассетах и так далее. Мы ищем ретро-новости по всему свету и доносим их до вас.
Почта для обратной связи: mail@idpixel.ru.
«Идеальному пикселю» нужны авторы
Новостной поток не иссякает ни на сутки, а времени и сил хватает далеко не на всё. Для развития сайту нужны новые авторы, поэтому если вы умеете и любите писать про ретро-игры и ретро-платформы — дайте нам знать.

Оставлять комментарии могут только авторизованные пользователи.